上手实战
前面已经介绍了爬虫的基础,这节我们对刚上映的某电影豆瓣影评进行实战。
首先打开豆瓣,找到电影短评界面
这个url就是我们要爬取的地址,直接上代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| import pandas as pd
import requests
from bs4 import BeautifulSoup
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/121.0.0.0 Safari/537.36'}
url="https://movie.douban.com/subject/26747919/comments"
pages=20
comments=[]
for page in range(pages):
r=requests.get(url=url+'?start='+str(page*20),headers=headers)
r.encoding='utf-8'
soup=BeautifulSoup(r.text,'lxml')
comment_elements=soup.find_all('span',{'class':'short'})
for element in comment_elements:
comments.append(element.text.strip())
data={'评论内容':comments}
df=pd.DataFrame(data)
output_filename="douban.xlsx"
df.to_excel(output_filename,index=False,engine='openpyxl')
print(f'Saved: {output_filename}')
|
爬取结果如下:
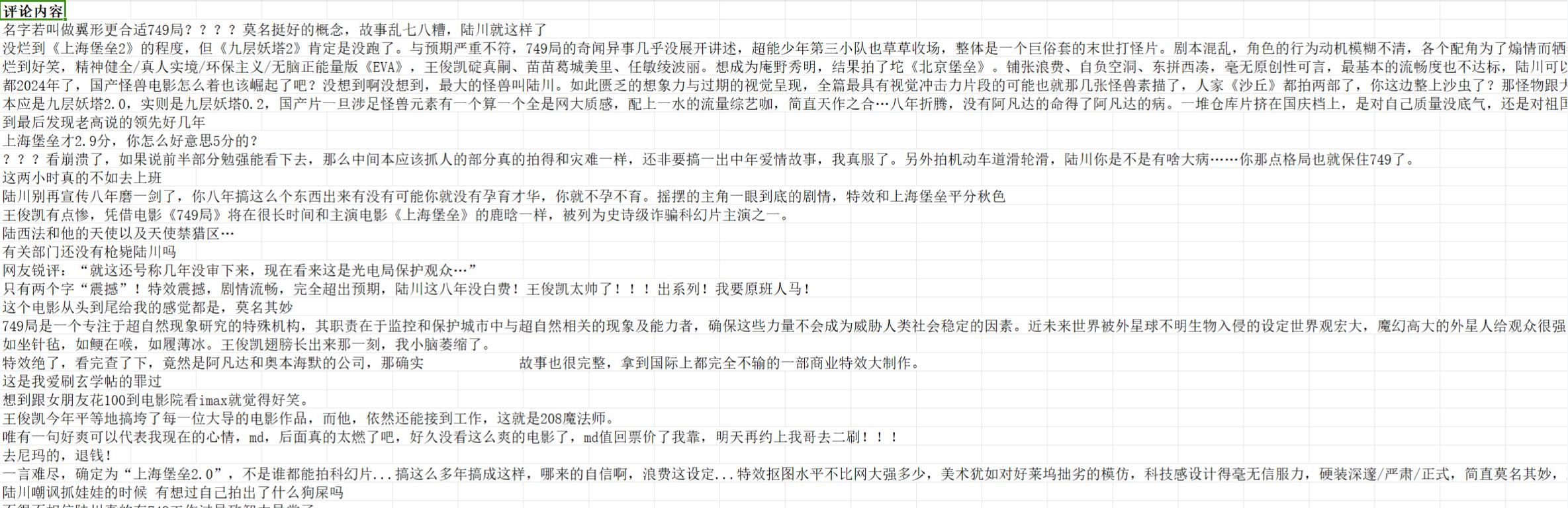
既然爬都爬了,这里就引入另一个有趣的方向 - - 自然语言处理之情感分析。
情感分析
这里先简单使用Snownlp以对情感分析有个基本的印象:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| from snownlp import SnowNLP
import pandas as pd
df=pd.read_excel('douban.xlsx')
df['情感分析']=df['评论内容'].apply(lambda x: SnowNLP(x).sentiments)
def categorize_sentiment(score):
if score>0.6:
return '正向'
elif score<0.4:
return '负向'
else:
return '中性'
df['情感分类']=df['情感分析'].apply(categorize_sentiment)
sentiment_counts=df['情感分类'].value_counts()
sentiment_proportion=df['情感分类'].value_counts(normalize=True)*100
print(df)
print("\n情感统计结果:")
print(sentiment_counts)
print("\n情感比例:")
print(sentiment_proportion)
|
结果如下:

很明显,存在很多不准确的情况。期待随着后面的学习,我们能够对其不断优化\( ^▽^ )/